
Data Warehouse vs Data Lake: What's the difference? Which do I need?
- Baleen Data Blog

- Aug 8, 2022
- 5 min read
We live in a buzzword heavy industry. To help clarify and maybe demystify, let's take a few minutes to discuss the differences between data warehouse and data lake repositories.
Food, clothing, shelter – these are basic human needs. Data has basic needs as well – primarily shelter. Just as the architecture of the different structures we occupy as humans affects the way we live and work, the architecture of data storage systems matters to the lifestyle of our data.

Data repositories today offer a nearly endless level of scalability and a wide range of storage styles. While this might sound great, it also means there are a lot of decisions to make that have a significant impact on your business. In this article we'll take a practical look at the differences, usage patterns, and benefits of two of today's major data architecture approaches: the data warehouse and the data lake.
Definitions & Structural Differences
While both warehouses and lakes are intended to aid in analyzing, reporting, and engineering, each has a different target audience and a unique architecture style. Deciding which of the two to use depends on two main factors: 1) the source of your data and 2) your usage needs.

Data warehouses are best analogized to a new home or commercial building: they have purpose-built sections and features like the living room, dining room, break room, kitchen, etc. In more technical language, a data warehouse is a relational data repository created to facilitate reporting and analysis. As such, it's organized, transformed, and aggregated into dimensions (descriptors) and measures (quantifiable numbers like sums and counts) that enable users to navigate and interpret the data with relative ease.
A specific data warehouse is tuned to extract data via queries, reports, dashboards, etc. in the shortest amount of time possible. This includes the use of structural integrity components such as primary keys, foreign keys, and indices, each of which helps keep data organized in line with the structural design of the database, all while avoiding corruption or conflict. A high degree of accuracy is designed into this to maintain ACID compliance (Atomicity, Consistency, Isolation, and Durability). ACID ensures that the warehouse exactly mimics and represents the source system used to populate it.
The original data warehouse design was created by William Inmon, followed by Ralph Kimball, who offered a slightly different design routine. Working in the 1980s and 1990s, each of them focused on dealing with the storage and computational limitations of the time. The style of organization was intended to make search and retrieval more efficient, but that came at the cost of flexibility.

The data lake is a newer data repository style created to handle larger amounts of data in a variety of structures and styles, ultimately allowing for use cases not possible in the highly structured world of data warehouses. Data lakes are more free flowing and organic in their structure, enabling flexibility of storage types.
A data lake is intended to store data sent continuously from multiple sources such as IoT sensors, application messaging queues, Web traffic, etc. These inputs are stored in raw, unchanged (immutable) formats, enabling the detailed analysis of unmodified transactions. James Dixon, who coined the term Data Lake back in 2010, described the architecture this way:
If you think of a data mart as a store of bottled water, cleansed and packaged and structured for easy consumption, the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.
In other words, data warehouses are designed to provide the singular, pre-determined version of what the data can show, packaged and ready for easy consumption. Data lakes are the raw, unchanged, unfiltered, streaming data that allows us deeper visibility into the source.
| Data Warehouse | Data Lake |
Architecture |
|
|
Database Type Examples |
|
|
Types of Data Stored | Structured Data
| Unstructured Data
|
Target User Audience |
|
|
Which do I need?
There are, of course, pros and cons to each of these data architecture styles. Implementing a data lake in the wrong situation can lead to potentially inaccessible data analysis or overly tedious reporting mechanisms. Similarly, a data warehouse in the wrong situation can result in a lack of visibility, little or no flexibility, and a diminishment in the usefulness of the data you're collecting and storing.
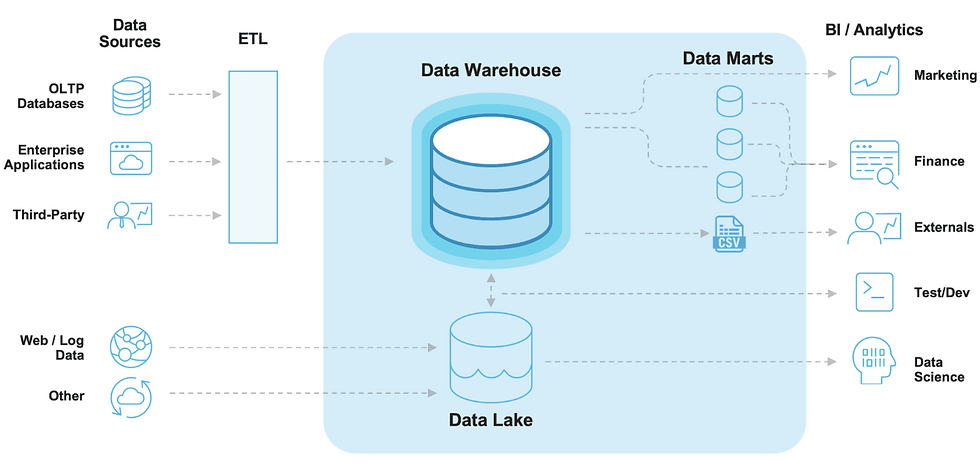
Deciding which is the best architecture style for your business requires a deeper understanding of the data generated by your business activities, your specific use-cases (both current and future), and the manner in which you measure and manage your business practices. In some cases, a hybrid approach can work to allow each use case access to data in their preferred structure, layout, and through the desired tooling. (i.e. IDE, Notebook, Report/Dashboard, Excel, etc.) There are also many platforms offering the flexibility to cultivate your data repository in any myriad of configurations and styles, leading us to hybrid solutions such as this Data Lakehouse from Databricks, but also available in Microsoft Azure, Amazon Web Services, Google Cloud Platform, & Snowflake.

Balancing your business' need for information with an appropriate level of system complexity optimizes your ability to turn the data you collect into meaningful insights to guide your business practices. The key is making the data accessible and functional to all who need it in a format they can use, but there are pitfalls along the way. Data pipelines that refresh repositories can be subject to problems with data integrity (transaction loss, duplication, etc.), poor data organization and cleanliness, and competing refresh cadences for batch and streaming data sources. Preplanning and the ability to recognize these pitfalls before falling into them can save you time, money, and frustration.
Final Word
All forms of data architecture aim to increase the efficiency of reporting, analysis, and decision-making. Both data warehouses and data lakes have beneficial features depending on the specific context of use. Choosing the correct architecture style for your situation requires forethought and expertise.
If you need better access to data and information but aren't sure where or how to start, the Baleen Data team is here to discuss your needs, answer your questions, create an architecture style tailored to your unique situation, and build out the repository your analysts and report writers need to be successful. Reach out to us to help your business teams thrive.