
Future of Data & Analytics
- Baleen Data Blog

- Mar 1, 2022
- 5 min read
Updated: Aug 15, 2022
Where did Data & Analytics originate? How have we gotten here? What comes next?
Knowledge is power. We all know this, and it's always been true. Where are the scarce sources of food? What kinds of weapons and strategies will defend us from our enemies? How can we harness the power of nature to make our lives more easeful and secure? Since the dawn of time, humans have sought to acquire and deploy knowledge for effective action, and those who did a better job of it prospered mightily.
The main difference between today and the rest of human history is the quantity of information available, the potentialities for the use of data, and the kinds of power that a dynamically adaptive system of knowledge can unleash. It's also more possible to get swamped by all of the available data. We all know this as well. The sheer volume of information generated each second in today's world can easily render us powerless in the face of its enormity. But that only makes skillful use of data that much more important. As the sources of data have multiplied and expanded, so too has the importance of leveraging knowledge into effective decision making.
The Use of Data, Then and Now
Data analytics, data engineering, business intelligence, and decision support systems are just a few of the names and techniques used in tracking the information generated by businesses as they operate. Originally stored for historical analysis, this information was used to answer the question: "What happened?"
We have now progressed into a predictive era, with the ability to ask a more useful question: "What happens next?" Prior results are good indicators of future behavior.
Let's start with a very quick review on the importance of data and how we used to prioritize based on technical limitations. A key turning point in the use of data came during the Civil War. With new telecommunications capabilities unavailable in previous wars – telegraph wires spanning the United States – commanders were able to gather information on conditions in the field and issue orders based on those conditions with an immediacy previously unavailable. Abraham Lincoln had a telegraph wire installed in the White House during the Civil War to receive faster battlefield updates. He would often sleep in the telegraph office during key battles in order to remain updated more frequently. This near real-time information is cited as a key reason for the outcome of the Civil War and made him our first high-tech commander-in-chief. Of course, there was still a very limited amount of data that could be transferred, and there weren't any very efficient methods of storing that data for future use.
Fast forward another century, when the concept of the data warehouse was first developed by Bill Inmon and Ralph Kimball, pioneers in methods of data storage and extraction. By the 1980s, computers were capable of transmitting and storing larger amounts of data than ever before, but there were still constraints on how that data could be effectively retrieved and analyzed. Their innovations allowed for a quantum leap forward in the effective leveraging of data at a time when storage and computational resources were limited. Up to that point, it simply wasn't cost effective to make retrievable all of the information an enterprise was capable of generating and storing. Their novel approaches to data warehousing revolutionized the entire data analysis industry; however, the technological limitations of the 1980s and 1990s required a series of compromises that left analysts wanting more detail, faster response times, and the ability to ask and answer a wider range of questions.
Breaking Barriers
While limitations on speed and storage capacity attenuated the ability of data analysts to make full use of the data being generated, there was widespread optimism that these limitations would soon be overcome—and the optimists were right.
Today's levels of computational power and data storage capability mean that there are essentially no more barriers to making use of a virtually infinite supply of data. In the 2020s, we have the ability to store, retrieve, and analyze data sets that would've crashed whole server farms in the times of Inmon and Kimball. At the same time, the cost and running time for storage, extraction, and analysis have fallen to extremely low levels. With today's technologies, data-set extraction and analysis can be done in a fraction of the time, for a fraction of the cost, available to us while working at home in pajamas.
Our ability to create meaningful analysis from and visualizations of data is unprecedented. There is a massive new library of tool options, methodologies that retain granularity of information while remaining responsive to our stream of consciousness questions.
An Even More Boundless Future
While the transformation of data analytics has been truly astounding over the past decade, there are yet greater improvements just over the horizon. Present trends indicate that in the near future, data will be fully democratized—most data sets will be publicly available, and analysis will be more automated, with new tools handling rote administrative tasks such as creating real-time backups, removing data-type conflicts, scrubbing superfluous commas, and cleaning up malformed strings from cross-referenced lists. Essentially all of the boring but important tasks of making data optimally useful will have been taken over by the tooling.
This will enable us, aided by automated Artificial Intelligence (AI), to ask or think native language questions and receive not only immediately useful answers but additional questions that can make use of drill-down capabilities to provide useful details. (Think Google search for your organization's data.) The data repositories supporting these kinds of queries will have moved away from Enterprise Data Warehouse or Enterprise Data Lake structures into something more similar to application data models, allowing AI to function deftly, operating like a neural network as it searches for patterns and correlations rather than relying on indexes and partitions driven by pure computational might.
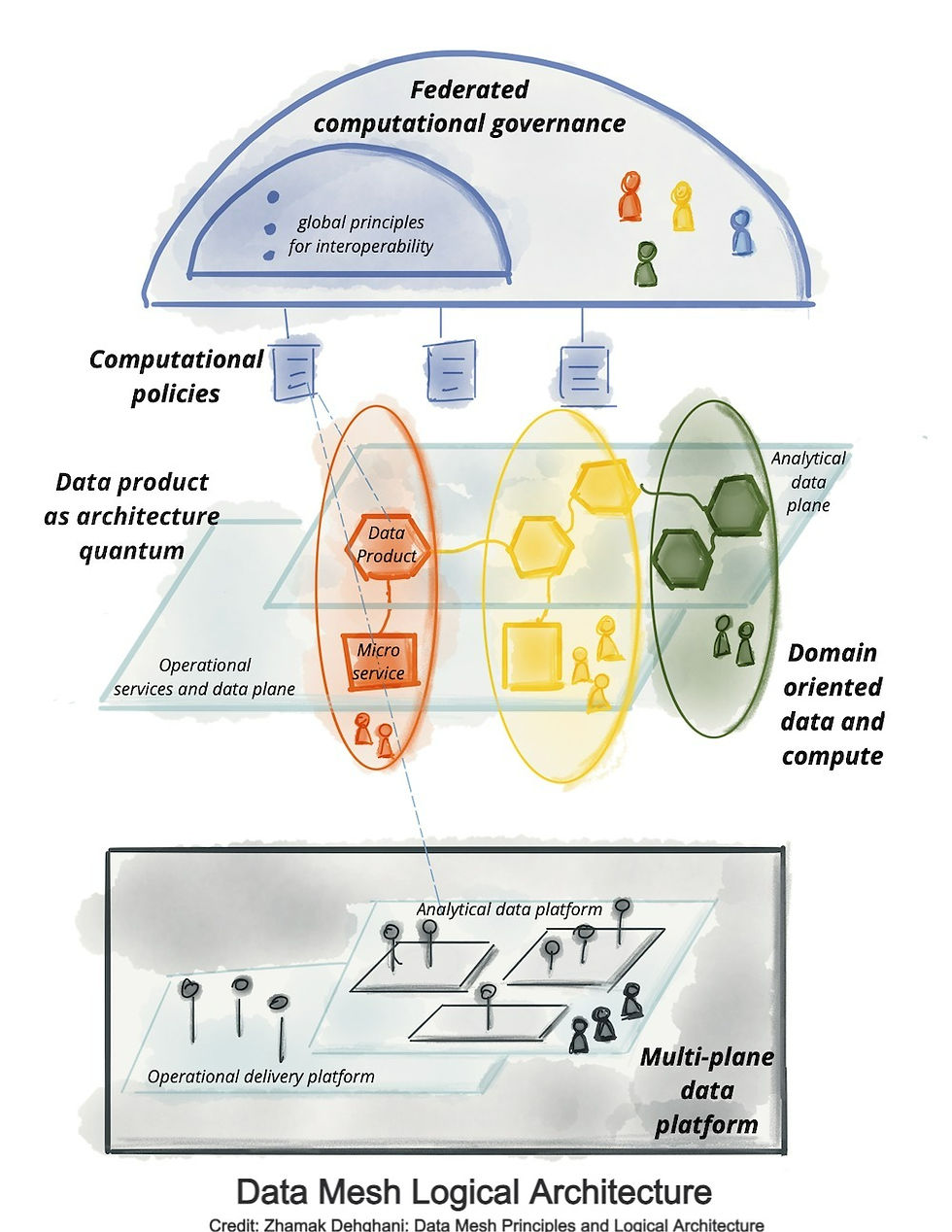
In this future scenario, something similar to a modern day Data Mesh architecture is the predominant implementation model. This hyper-distributed architecture allows for democratization of data, placing it in the hands of each department or regional organization to operate at lighting speed without the need for centralized IT oversight or support. This exceptionally localized data enables business to operate without restrictions or wait times to create new data repositories and analytics, enabling rapid decision making right at the point of impact. Imagine, for example, an IT-enabled doorbell that analyzes your body temperature and other vital signs as you walk in the door, sends this data to your preferred pharmacy, who automatically delivers you treatment options based on your symptoms and order history. When they arrive you chose to accept or return them with the returned items going back to the pharmacy on the delivery drone. Similarly, bank fraud and identity theft can be driven to extinction as financial institutions can track the exact location of your card and person, allowing for real-time authorization of transactions through telemetry analysis in sub-second response times in a fully scalable way. And these are just a few of the benefits we can currently imagine. We don't fully know yet what we might be able to do when data-analysis limitations are fully overcome.
Final Word
There is a lot to be hopeful about the future in Data & Analytics. Tooling will continue to be more accessible, resource costs flexible, & handling techniques improved. As asked earlier in this article, what are we going to do with these new tools & techniques? What are you going to do? If unsure, reach out to Baleen Data's Data & Analytics team to discuss.